
{kind=link}
The Rise of Self-Supervised Learning in Video Representation: A Deep Dive
In the rapidly evolving landscape of artificial intelligence, transfer learning from pretrained models on ImageNet has become the gold standard in computer vision. While self-supervised learning has taken the lead in natural language processing, its potential in computer vision, particularly in video analysis, is gaining traction. This article explores the nuances of self-supervised learning, its distinction from transfer learning, and its application in video-based tasks.
Understanding Self-Supervised Learning
What is Self-Supervised Learning?
Self-supervised learning is a paradigm where a model learns to predict part of its input from other parts, effectively generating its own supervisory signal from the data itself. This approach is particularly useful in scenarios where labeled data is scarce or expensive to obtain. In contrast to traditional supervised learning, where models are trained on labeled datasets, self-supervised learning leverages the inherent structure of the data to create labels automatically.
Self-Supervised Learning vs. Transfer Learning
Transfer learning involves taking a model trained on one task (Task A) and fine-tuning it for another related task (Task B). The pretraining phase allows the model to learn general features that can be beneficial for the new task. However, in domains like video analysis, obtaining annotated data for transfer learning can be challenging.
Self-supervised learning, on the other hand, allows for weight transfer by pretraining models on tasks where labels are generated from the data itself. This method is particularly advantageous in video analysis, where vast amounts of unlabeled data are readily available.
To illustrate the difference, consider the following diagram:

In essence, self-supervised learning creates a pretext task that helps the model learn useful representations, which can then be applied to a downstream task.
Designing Self-Supervised Tasks
Pretext and Downstream Tasks
In self-supervised learning, the pretext task is the artificially created task that the model learns from, while the downstream task is the actual task we want to solve. For video analysis, these tasks can be categorized into sequence prediction and verification.
For instance, a common pretext task in video analysis is to predict the correct order of shuffled video frames. This requires the model to understand the temporal relationships between frames, which is crucial for tasks like action recognition.
Importance of Temporal Structure
When dealing with videos, the temporal dimension adds complexity. The model must learn not only from spatial features but also from the temporal coherence of the sequences. This leads to questions such as:
- How does the model learn from the spatiotemporal structure present in the video without using supervised semantic labels?
- Are the representations learned using unsupervised spatiotemporal information meaningful?
- Are these representations complementary to those learned from strongly supervised image data?
These questions highlight the need for well-designed self-supervised tasks that can effectively capture the temporal dynamics of video data.
Notable Self-Supervised Learning Approaches in Video Analysis
Shuffle and Learn: Temporal Order Verification
One of the pioneering works in self-supervised video representation learning is the "Shuffle and Learn" approach by Misra et al. (2016). This method formulates the pretext task as a sequence verification problem, where the model predicts whether a sequence of video frames is in the correct temporal order. By sampling frames with high motion and creating positive and negative tuples, the model learns to differentiate between correct and incorrect sequences.
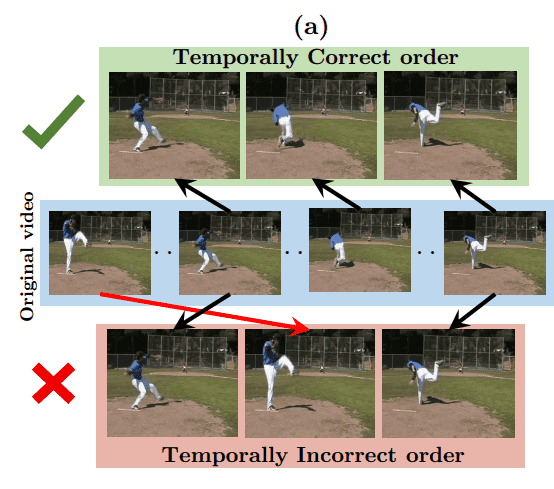
Unsupervised Representation Learning by Sorting Sequences
Lee et al. (2017) extended the previous work by proposing an Order Prediction Network (OPN) to solve the sequence sorting task. This approach involves sorting shuffled image sequences and casting the problem as a multi-class classification task. By leveraging pairwise feature extraction, the model learns richer and more generalizable visual representations.
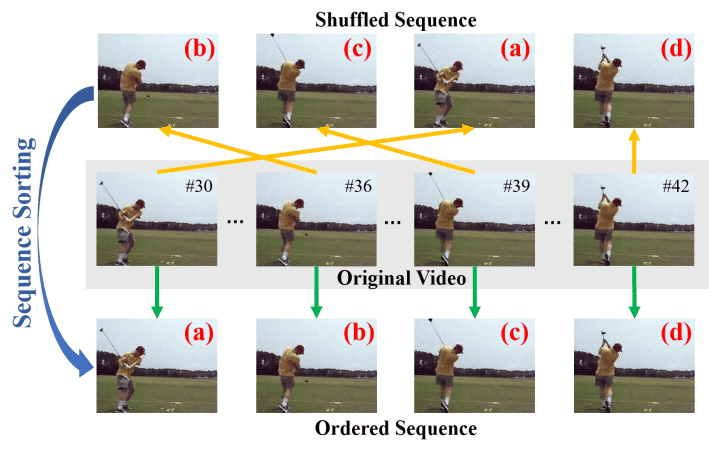
Odd-One-Out Networks
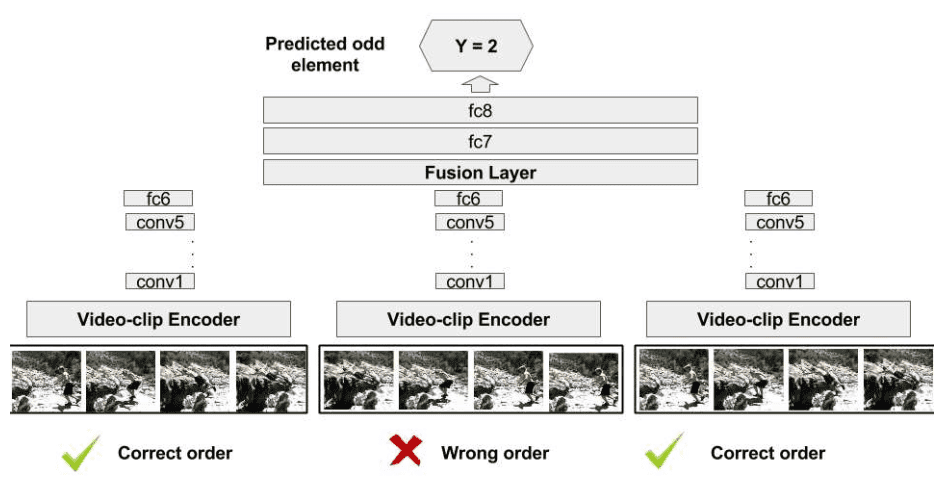
In 2017, Fernando et al. introduced the Odd-One-Out Network (O3N), which aims to predict the odd element from a set of related elements. This task requires the model to compare multiple inputs and discern which one does not belong, fostering a deeper understanding of the relationships between video segments.
Self-Supervised Spatiotemporal Learning via Video Clip Order Prediction
Xu et al. (2019) proposed a method that integrates 3D CNNs for clip order prediction. By sampling fixed-length clips from videos and shuffling them, the model learns to predict the correct order, enhancing its ability to extract meaningful features from video data.
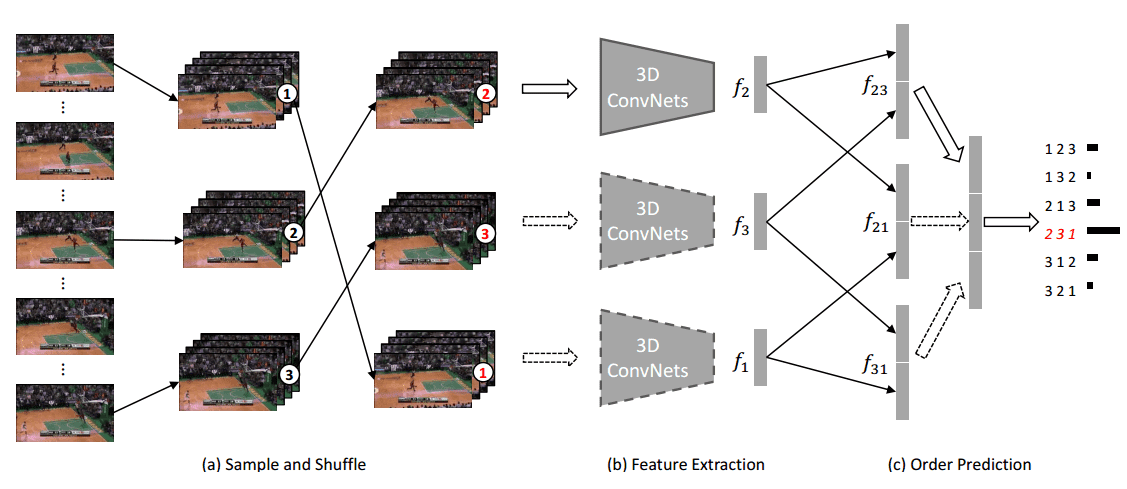
Conclusion
Self-supervised learning is paving the way for innovative approaches in video representation learning. By leveraging the inherent structure of unlabeled data, researchers can design effective pretext tasks that enhance the model’s understanding of temporal dynamics. As we continue to explore this exciting field, we can expect to see more applications and advancements that push the boundaries of what is possible in computer vision.
TL;DR
- Self-supervised learning creates supervisory signals from data itself, unlike transfer learning, which relies on labeled datasets.
- Well-designed self-supervised tasks are crucial for learning meaningful representations in video analysis.
- Notable approaches include temporal order verification, sequence sorting, odd-one-out networks, and clip order prediction.
- The future of self-supervised learning in video representation is promising, with potential applications across various domains.
For those interested in delving deeper into self-supervised learning, I recommend exploring the works cited in this article and keeping an eye on emerging research in this dynamic field.