
{kind=link}
Understanding the Receptive Field in Deep Convolutional Architectures
In this article, we will explore the concept of the receptive field within deep convolutional architectures, drawing parallels to the human visual system and discussing its implications in computer vision tasks. The terminology used in deep learning often finds its roots in neuroscience, and understanding the receptive field is crucial for anyone looking to develop or analyze deep learning models effectively. By the end of this article, you will have a comprehensive understanding of how to calculate the receptive field of your model and the most effective strategies to increase it. Let’s dive in!
What is the Receptive Field?
According to Wikipedia, the receptive field of a biological neuron is defined as “the portion of the sensory space that can elicit neuronal responses when stimulated.” In simpler terms, it refers to the specific area of input that influences the activity of a neuron. For instance, in the context of the human visual system, each neuron in the retina responds to light from a particular region of the visual field, contributing to our perception of images.
The human visual system can process approximately 10 to 12 images per second, perceiving them individually, while higher rates are interpreted as motion. This processing ability is influenced by the receptive fields of the neurons involved, which collectively form our field of view.
Source: Brain Connection
In the context of deep learning, the receptive field (RF) refers to the size of the region in the input that produces a specific feature in the output. It serves as a measure of how much of the input is considered when generating a feature at any given layer of the network.
The Importance of the Receptive Field in Deep Learning
Understanding the receptive field is essential for several reasons, particularly in dense prediction tasks such as image segmentation and object detection. In these tasks, we aim to produce predictions for each pixel in the input image, which requires a sufficiently large receptive field to capture all relevant information.
For example, when segmenting an object like a car or a tumor, it is crucial that the model has access to the entire relevant area of the input image. A small receptive field may overlook important contextual information, leading to inaccurate predictions.
Source: Nvidia’s Blog
In object detection, a model with a limited receptive field may struggle to recognize larger objects, which is why multi-scale approaches are often employed. Additionally, in motion-based tasks like optical flow estimation, the receptive field must be large enough to capture significant pixel displacements.
Measuring the Receptive Field
To measure the receptive field of a convolutional network, we can use closed-form calculations, particularly for single-path networks without skip connections. The receptive field can be calculated recursively for each layer based on the kernel size and stride. For two sequential convolutional layers, the relationship can be expressed as:
[ r_1 = s_2 \times r_2 + (k_2 – s_2) ]
In a more general form, for ( L ) layers, the receptive field can be calculated as:
[ r0 = \sum{i=1}^{L} \left( (ki – 1) \prod{j=1}^{l-1} s_j \right) + 1 ]
Where ( r_0 ) denotes the desired receptive field of the architecture.
Strategies to Increase the Receptive Field
There are several effective strategies to increase the receptive field in a convolutional network:
-
Add More Convolutional Layers: Each additional layer increases the receptive field size linearly, as each layer contributes the kernel size to the overall receptive field.
-
Add Pooling Layers or Higher Stride Convolutions: Pooling layers and convolutions with larger strides can increase the receptive field size multiplicatively, allowing the model to capture broader contextual information.
-
Use Dilated Convolutions: Dilated convolutions introduce a dilation rate, which effectively increases the receptive field without increasing the number of parameters. This allows for a more extensive coverage of the input space while maintaining resolution.
- Depth-wise Convolutions: These convolutions operate on each input channel separately, allowing for a more compact representation and enabling the addition of more layers, which can further increase the receptive field.
Understanding Dilated Convolutions
Dilated convolutions expand the receptive field exponentially while keeping the number of parameters linear. By introducing "holes" in the convolutional kernel, dilated convolutions allow for a wider coverage of the input without losing resolution.
For example, a 3×3 kernel with a dilation rate of 2 will have the same receptive field as a 5×5 kernel, but with fewer parameters. This property makes dilated convolutions particularly useful in deep architectures.
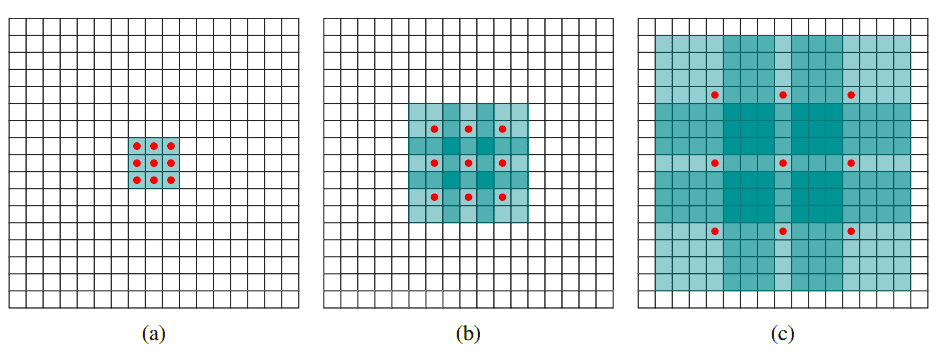
Source: Yu et al. 2015
Skip Connections and Receptive Field
In architectures that utilize skip connections, the receptive field can vary significantly. While skip connections provide multiple paths for information flow, they can also lead to a smaller effective receptive field. For instance, in the HighResNet architecture, the maximum receptive field can reach up to 87 pixels, but the effective receptive field may be smaller due to the nature of the connections.
Understanding the Effective Receptive Field
The effective receptive field (ERF) refers to the actual contribution of each pixel in the receptive field to the output feature. Research has shown that not all pixels contribute equally; central pixels tend to have a more significant impact due to the multiple paths available for information propagation.
The ERF can be visualized as a Gaussian distribution, where central pixels have a higher influence on the output, while peripheral pixels contribute less. This understanding is crucial for optimizing model performance, as it highlights the importance of central pixels in feature extraction.
Conclusion
In this article, we explored the concept of the receptive field in deep convolutional networks, starting from its biological roots in the human visual system. We discussed how to measure the receptive field, strategies to increase it, and the implications of skip connections and effective receptive fields.
Key Takeaways:
- The receptive field is crucial for local operations in convolutional networks.
- A well-designed model should have a receptive field that covers the entire relevant input region.
- Dilated convolutions and pooling operations are effective methods for increasing the receptive field.
- The effective receptive field often grows slower than theoretical calculations, emphasizing the importance of training.
Understanding the receptive field is an ongoing area of research that continues to provide insights into the workings of deep convolutional networks. By mastering these fundamentals, you can enhance your ability to design and analyze effective deep learning models.
Additional Resources
For further exploration of the receptive field and its implications, consider the following resources:
- Kobayashi et al. 2020: Interpretation of ResNet by Visualization of Preferred Stimulus in Receptive Fields.
- Pytorch Toolkit: A toolkit for measuring the receptive field in Pytorch.
- Tensorflow Toolkit: A toolkit for measuring the receptive field in Tensorflow.
By understanding and leveraging the concept of the receptive field, you can significantly improve the performance and effectiveness of your deep learning models.