
{kind=link}
Human Pose Estimation: A Deep Dive into Computer Vision
Human Pose Estimation (HPE) has emerged as a pivotal task in the realm of computer vision, capturing significant attention over the past few years. This technology has a vast array of applications, ranging from human-computer interaction and gaming to action recognition, computer-assisted living, and special effects in film and media. The rapid advancements in HPE can largely be attributed to the rise of neural networks during the deep learning era, which has transformed how we approach this complex problem.
So, What is Human Pose Estimation?
At its core, human pose estimation aims to determine the locations of joints in one or more human bodies within a 2D or 3D space based on a single image. By connecting these joints, we can create a skeletal representation that effectively describes the pose of a person. This task is crucial for understanding human movement and interaction in various contexts.
Key Approaches in Human Pose Estimation
In this article, we will explore some of the most popular and recent works in both 2D and 3D human pose estimation.
OpenPose: The Pioneer in Pose Detection
OpenPose stands out as one of the most widely used open-source tools for detecting body, foot, hand, and facial keypoints. It employs Part Affinity Fields (PAFs), which are 2D vector fields that encode the location and orientation of limbs across the image domain. The architecture processes an input image through several convolutional layers to generate PAFs and confidence maps for each joint location. This iterative refinement process allows OpenPose to produce highly accurate predictions, making it a staple in many research projects.
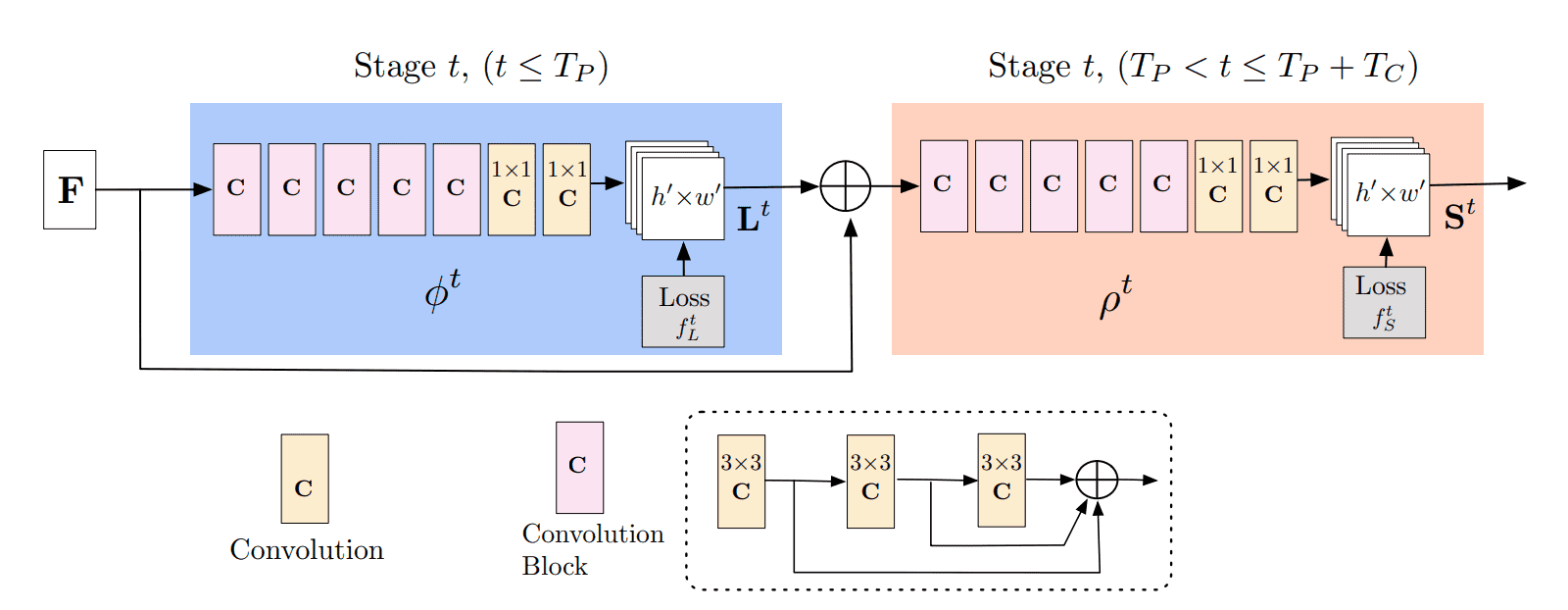
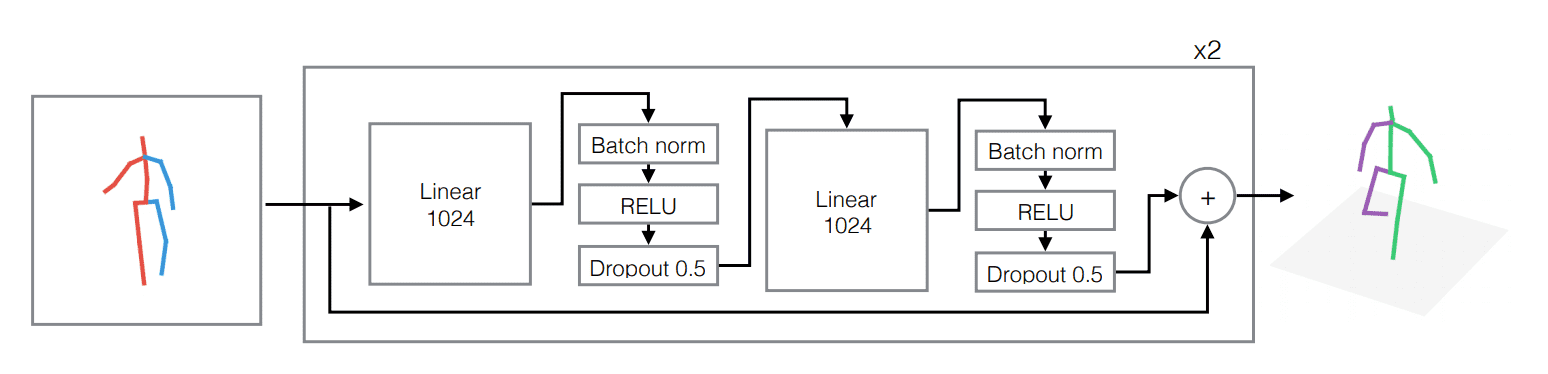
3D Pose Estimation: Advancements in Motion Capture
Recent advancements in 3D human pose estimation have led to the development of lightweight networks capable of processing up to 300 frames per second. These networks extract 2D joint locations and utilize simple neural networks to estimate the coordinates of joints in 3D space. This approach significantly enhances the efficiency and accuracy of motion capture systems.
DensePose: Dense Human Pose Estimation in the Wild
DensePose takes a step further by adopting the architecture of Mask-RCNN combined with Feature Pyramid Networks (FPN) to achieve dense part labels and coordinates within selected regions. This method utilizes a fully-convolutional network on top of ROI-pooling to generate per-pixel classification results for surface part selection and local coordinate regression.
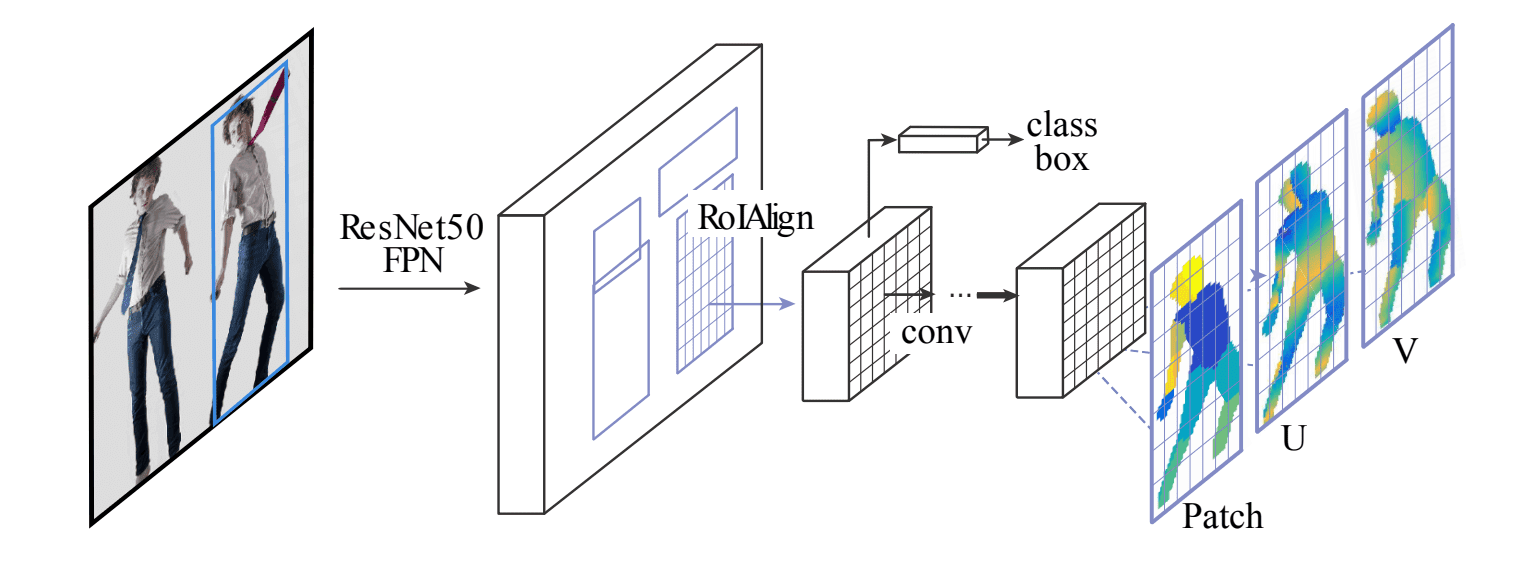
The DensePose-RCNN system is trained using annotated points as supervision, but it achieves superior results by employing a learning-based approach to fill in unannotated areas. This innovative technique enhances the model’s ability to generalize across diverse scenarios.
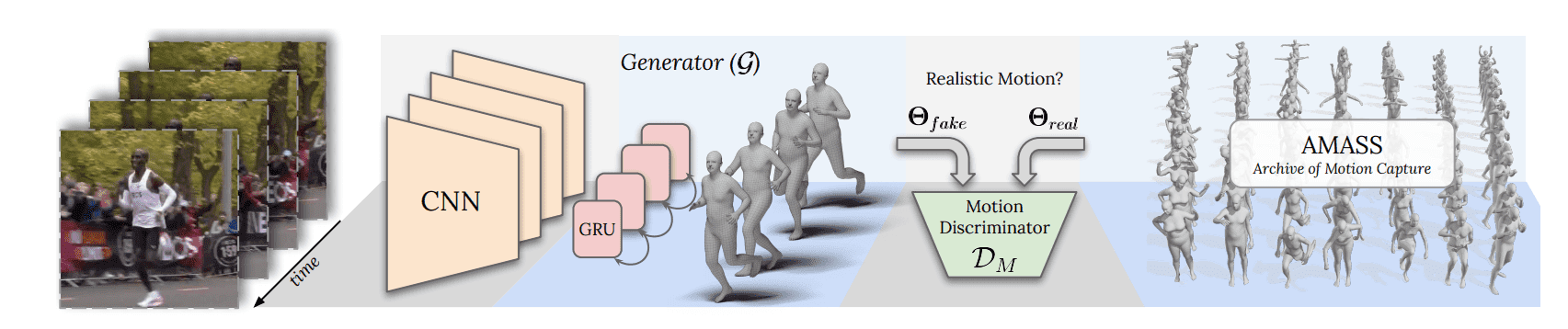
VIBE: Video-Based Human Pose and Shape Estimation
VIBE represents a significant leap in human pose estimation by focusing on video sequences rather than static images. This framework utilizes a temporal network to produce kinematically plausible human motion. By leveraging a generative adversarial network (GAN), VIBE predicts human pose and shape parameters for each frame while a motion discriminator distinguishes between real and regressed sequences.
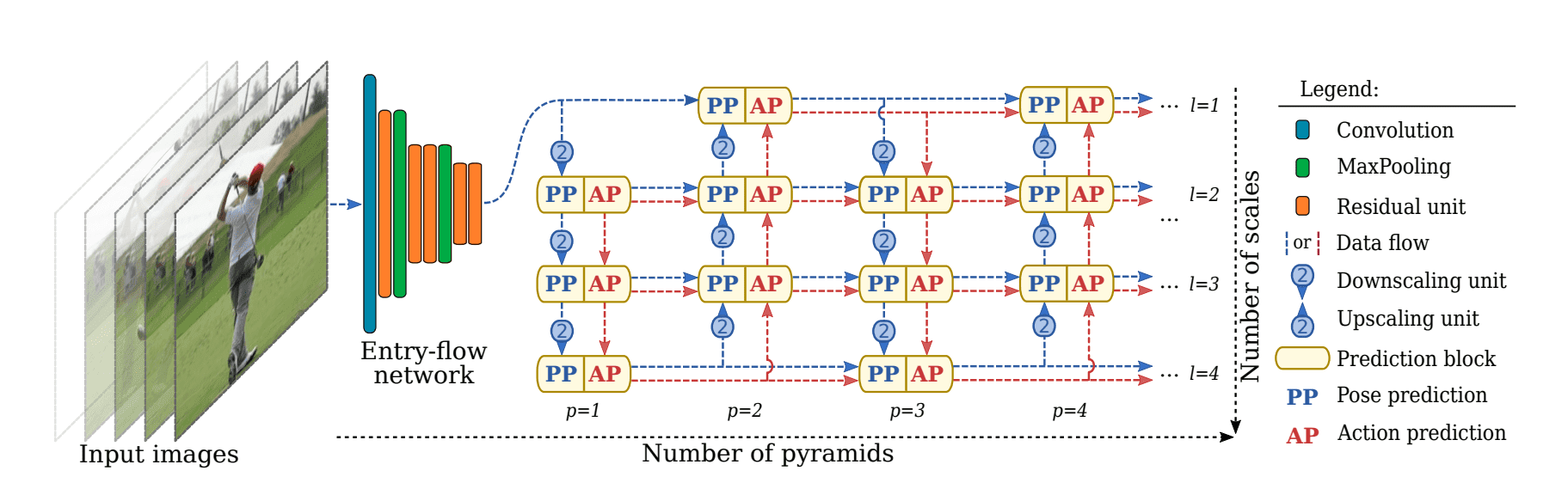
Multi-Task Learning for Pose Estimation and Action Recognition
A multi-task framework has been developed to jointly estimate 2D or 3D human poses from monocular color images while classifying human actions from video sequences. This unified approach refines both pose and action predictions through a series of prediction blocks, enhancing the model’s overall performance.
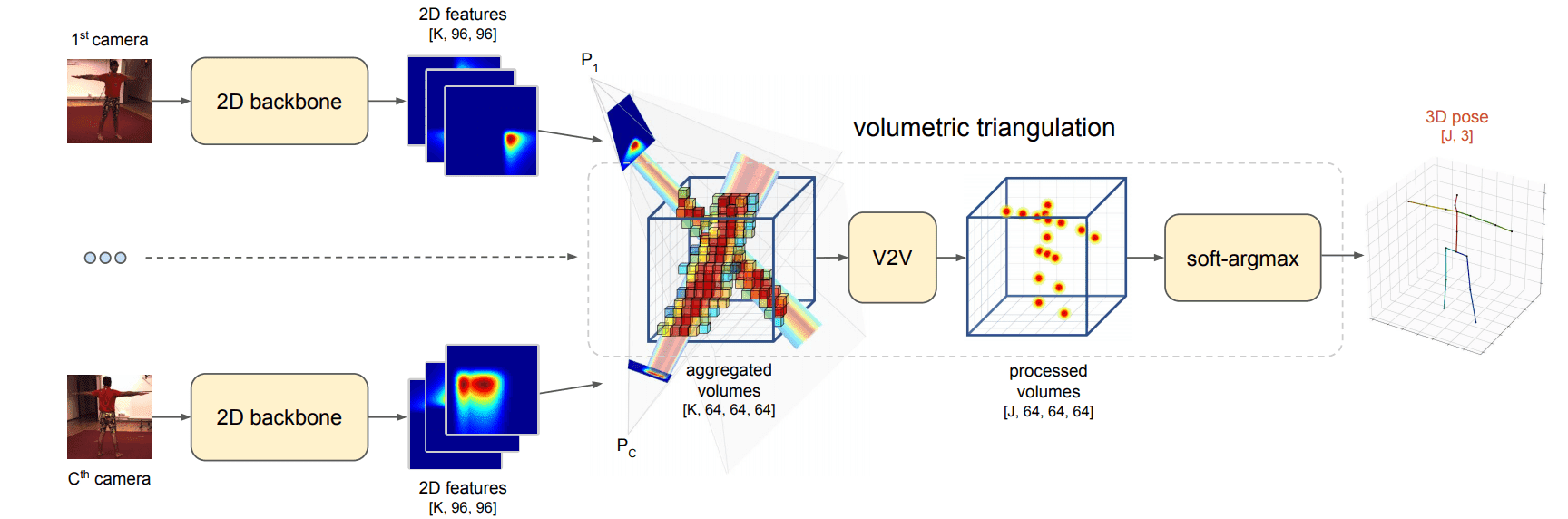
Multi-View Approaches: Algebraic and Volumetric Triangulation
To achieve more precise pose estimation, multi-view approaches utilize multiple cameras from different angles. Two notable methods are algebraic triangulation and volumetric triangulation.
Algebraic Triangulation
In this method, RGB images are processed through a 2D CNN to extract joint heatmaps and confidence scores. A linear algebraic triangulation algorithm then estimates the 3D locations of joints, considering the independence of joint coordinates from each camera view.

Volumetric Triangulation
This approach projects feature maps into 3D volumes, filling a fixed-size 3D cube around the person with outputs from the 2D network. The aggregated volumetric maps are fed into a 3D convolutional neural network, which outputs 3D heatmaps for joint location estimation. This method currently represents the state-of-the-art in the Human3.6M dataset, the largest dataset for human poses.
Conclusion
In this article, we explored some of the most significant advancements in human pose estimation, highlighting the transformative impact of deep learning on this field. As technology continues to evolve, we can anticipate even more innovative solutions that will enhance our understanding of human movement and interaction.
For those interested in delving deeper into computer vision with deep learning, the Advanced Computer Vision with TensorFlow course by DeepLearning.ai offers an excellent opportunity to expand your knowledge and skills.
References
Sarafianos, Nikolas, Boteanu, Bogdan, Ionescu, Bogdan, & Kakadiaris, Ioannis. (2016). 3D Human Pose Estimation: A Review of the Literature and Analysis of Covariates. Computer Vision and Image Understanding, 152. DOI: 10.1016/j.cviu.2016.09.002.
Disclosure: Please note that some of the links above might be affiliate links, and at no additional cost to you, we will earn a commission if you decide to make a purchase after clicking through.