: Fundamental Concepts and Various Methods")
{kind=link}
Neural Architecture Search (NAS): Automating the Design of Neural Networks
Neural Architecture Search (NAS) is a revolutionary approach in the field of deep learning that automates the design of neural network architectures. The primary aim of NAS is to optimize the topology of neural networks to achieve superior performance on specific tasks while minimizing human intervention and resource consumption. This article delves into the general framework of NAS, its various search strategies, and the latest advancements in the field.
Understanding the NAS Framework
At its core, NAS is a search algorithm that operates within a defined search space of potential network architectures. This search space comprises a list of predefined operations, such as convolutional layers, recurrent layers, pooling layers, and fully connected layers, along with their possible connections. A controller is responsible for selecting candidate architectures from this search space. These candidates are then trained and evaluated based on their performance on a validation dataset, and the results are used to refine the search process iteratively until an optimal architecture is identified.
The optimal architecture is subsequently evaluated on a test set to ensure its effectiveness. The iterative nature of this process allows NAS to explore a vast array of architectures efficiently, ultimately leading to the discovery of high-performing models.
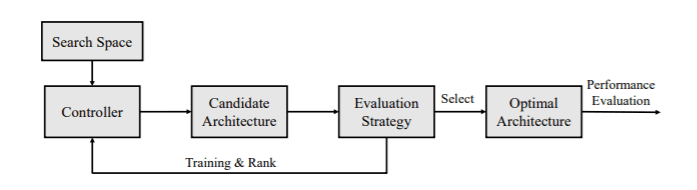
The Landscape of NAS Algorithms
The landscape of NAS algorithms can be quite complex, but they can generally be categorized based on three major components:
- Search Space: The set of possible architectures that can be explored.
- Search Strategy: The methodology used to navigate the search space, including the type of controller and the evaluation of candidate architectures.
- Performance Evaluation Technique: The metrics and methods used to assess the performance of candidate architectures.
Recent approaches have blurred the lines between search strategies and evaluation techniques, making it challenging to classify algorithms strictly. Therefore, we will focus on categorizing NAS algorithms based solely on their search strategies, which can be divided into five main areas:
- Random Search
- Reinforcement Learning
- Evolutionary Algorithms
- Sequential Model-Based Optimization
- Gradient Optimization
Random Search
The simplest approach to NAS is random search, which serves as a baseline. In this method, valid architectures are selected at random without any learning involved. While this approach is straightforward, it is often inefficient due to the vast search space.
Reinforcement Learning
NAS can be elegantly framed as a reinforcement learning (RL) problem. In this context, the agent’s action involves generating a neural architecture, while the reward is based on the architecture’s performance. Various RL methods can be employed to tackle this problem.
Early works in NAS, such as NAS-RL and NASNet, utilized recurrent neural networks (RNNs) as policy networks (controllers) to generate candidate architectures. The RNN’s parameters are optimized to maximize expected validation accuracy using policy gradient techniques like REINFORCE and Proximal Policy Optimization (PPO).
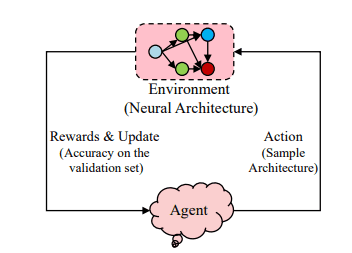
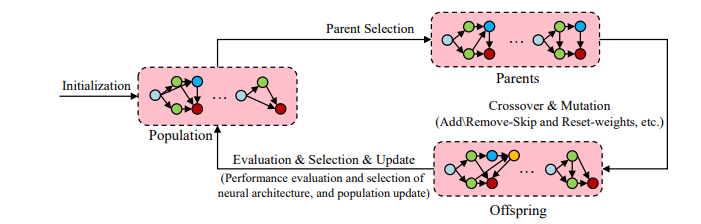
Evolutionary Algorithms
Evolutionary algorithms, such as Genetic Algorithms (GA), offer an alternative approach to optimizing neural architectures. These algorithms begin with a population of models and iteratively sample and reproduce models by applying mutations. Mutations may involve adding layers or modifying hyperparameters. After training, the models are evaluated and reintegrated into the population, repeating the process until a satisfactory architecture is found.
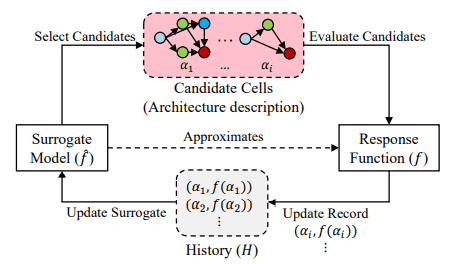
Sequential Model-Based Optimization
In sequential model-based optimization, NAS is viewed as an iterative process that builds increasingly complex networks. A surrogate model evaluates candidate modules and selects promising candidates, which are then trained and evaluated. This iterative refinement allows for the gradual expansion of the model’s complexity.
Gradient Optimization and One-Shot Approaches
Gradient optimization methods often utilize a one-shot model, also known as a supermodel or supernet. This single large network encompasses all possible operations in the search space and generates weights for various candidate networks. After training, sub-architectures can be sampled and compared on the validation set, leveraging parameter sharing to maximize efficiency.
One notable advancement in this area is DARTS (Differentiable Architecture Search), which transforms the search space into a continuous and differentiable form. DARTS formulates the discrete choice of operations as a softmax, allowing for joint optimization of architecture parameters and network weights through gradient descent.
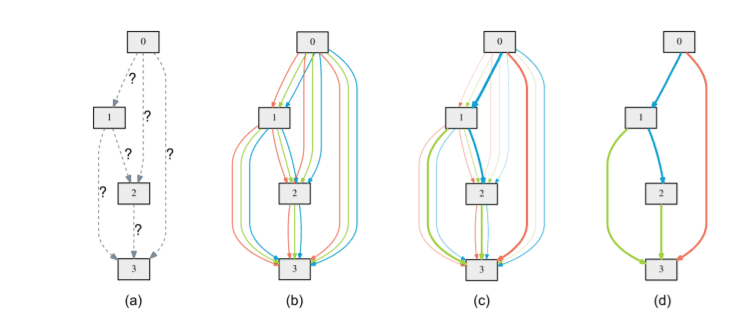
Implementation with Neural Network Intelligence (NNI)
To illustrate the practical application of NAS, we can utilize the Neural Network Intelligence (NNI) package developed by Microsoft. NNI supports various NAS methods, including DARTS, ENAS, and ProxylessNAS, among others.
For instance, in a DARTS implementation, a supergraph is defined as the search space, where each cell is represented as a Directed Acyclic Graph (DAG). The NNI library provides modules like LayerChoice and InputChoice to explore different layers and connections within the supermodel.
Here’s a simplified code snippet to demonstrate how to declare a supergraph using NNI:
import torch.nn.functional as F
import nni.retiarii.nn.pytorch as nn
class Net(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.LayerChoice([nn.Conv2d(3, 6, 3, padding=1), nn.Conv2d(3, 6, 5, padding=2)])
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.LayerChoice([nn.Conv2d(6, 16, 3, padding=1), nn.Conv2d(6, 16, 5, padding=2)])
self.conv3 = nn.Conv2d(16, 16, 1)
self.skipconnect = nn.InputChoice(n_candidates=2)
self.bn = nn.BatchNorm2d(16)
self.gap = nn.AdaptiveAvgPool2d(4)
self.fc1 = nn.Linear(16 * 4 * 4, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
bs = x.size(0)
x = self.pool(F.relu(self.conv1(x)))
x0 = F.relu(self.conv2(x))
x1 = F.relu(self.conv3(x0))
x1 = self.skipconnect([x1, x1 + x0])
x = self.pool(self.bn(x1))
x = self.gap(x).view(bs, -1)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
model = Net()Once the supergraph is defined, we can initiate the NAS training process using the DartsTrainer class, specifying the loss function, optimizer, and other training parameters.
Conclusion
Neural Architecture Search is a rapidly evolving field with immense potential to enhance the efficiency and performance of deep learning models. While the research is still in its early stages, the advancements made thus far are promising. The complexity of benchmarking NAS algorithms and the limited availability of open-source libraries pose challenges, but initiatives like NNI are paving the way for broader adoption and experimentation.
As NAS continues to develop, it is crucial for researchers and practitioners to explore its capabilities and contribute to its growth. By automating the design of neural networks, NAS holds the promise of unlocking new frontiers in artificial intelligence and machine learning.
For further exploration of NAS and its implementations, consider checking out the resources mentioned throughout this article, including the NNI library and various research papers. Your journey into the world of Neural Architecture Search awaits!