
{kind=link}
Understanding Image Segmentation: The Power of Semantic Segmentation in Computer Vision
Image segmentation is a cornerstone of computer vision, standing alongside object recognition and detection as one of the fundamental tasks in the field. At its core, semantic segmentation aims to classify each pixel in an image into a specific category, allowing for a more granular understanding of the visual content. Unlike traditional image classification, which assigns a single label to an entire image, semantic segmentation delves deeper, providing a label for every individual pixel based on the context of various objects present in the image.
What is Semantic Segmentation?
In semantic segmentation, we work with a predefined set of categories and assign a label to each pixel in the image. For instance, in a street scene, pixels might be labeled as red for pedestrians, blue for cars, and green for trees. This pixel-wise classification enables machines to understand and interpret images in a way that is more aligned with human perception.

While semantic segmentation focuses on classifying pixels into categories, it is essential to distinguish it from instance segmentation. In instance segmentation, different instances of the same class are labeled distinctly. For example, in a crowded scene, each person would receive a unique label, allowing for a more detailed analysis of the image.
Why is Semantic Segmentation Important?
You might wonder, "Why do we need such detailed processing?" The answer lies in the diverse applications of semantic segmentation. One of the most prominent applications is in self-driving cars, which rely on a comprehensive understanding of their surroundings. These vehicles need to identify every pixel in their field of view to navigate safely and efficiently.
Other notable applications include:
- Robotics: Both industrial and service robots utilize semantic segmentation for object recognition and manipulation.
- Geosensing: Analyzing satellite images for land use and environmental monitoring.
- Agriculture: Assessing crop health and yield predictions through aerial imagery.
- Medical Imaging: Assisting in diagnostics by segmenting anatomical structures in scans.
- Facial Segmentation: Enhancing facial recognition systems by accurately identifying facial features.
- Fashion: Enabling virtual try-ons and personalized recommendations based on clothing segmentation.
Approaching Semantic Segmentation with Deep Learning
The advent of deep learning has revolutionized computer vision, particularly in image classification tasks. Since 2012, deep neural networks have consistently outperformed traditional methods, leading to the widespread adoption of these techniques for semantic segmentation.
Defining the Problem
To effectively tackle semantic segmentation, we need to establish clear objectives:
- Each pixel of the image must be assigned to a class and colorized accordingly.
- The input and output images should maintain the same dimensions.
- Each pixel in the input must correspond to a pixel in the exact same location in the output.
- Pixel-level accuracy is crucial for distinguishing between different classes.
Fully Convolutional Networks (FCN)
The first significant breakthrough in semantic segmentation came with the introduction of Fully Convolutional Networks (FCN). Unlike traditional neural networks, FCNs consist solely of convolutional and pooling layers, eliminating the need for fully connected layers. This architecture allows for the mapping of input images to output segmentations effectively.

While FCNs produced promising results, they were computationally expensive. The challenge arose from the necessity to maintain image resolution without downsampling, leading to inefficiencies. To address this, researchers proposed an encoder-decoder architecture, where the encoder captures semantic information through downsampling, and the decoder recovers spatial information through upsampling.
The Role of Skip Connections
To enhance the quality of segmentation, skip connections were introduced. These connections bypass certain layers, allowing information from earlier layers to be passed directly to later layers. This technique improves the detail and accuracy of segmentation, particularly in defining edges and boundaries.
U-Net: A Game Changer in Semantic Segmentation
Building on the concepts of FCNs and skip connections, U-Net emerged as a powerful architecture specifically designed for biomedical image segmentation. U-Net introduces symmetry in the encoder-decoder structure, allowing for a more efficient transfer of information.
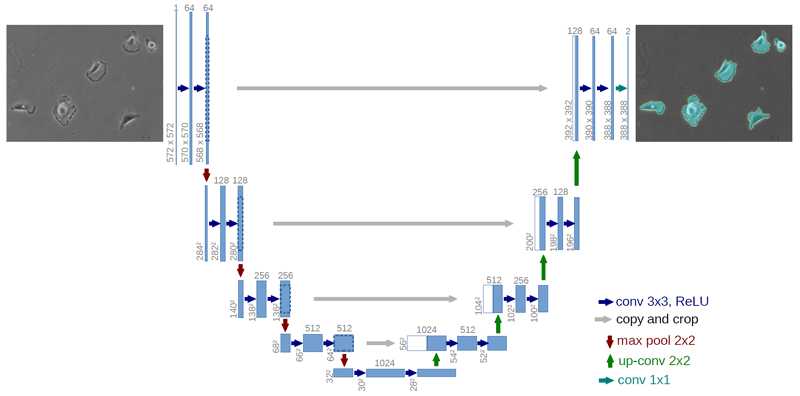
The U-Net architecture enhances the resolution of the final output by concatenating feature maps from the encoder with those from the decoder, resulting in a more detailed segmentation.
Implementing U-Net in Python
To illustrate the simplicity of implementing U-Net, here’s a basic example using Python and the Keras framework:
def unet(pretrained_weights=None, input_size=(256, 256, 1)):
inputs = Input(input_size)
conv1 = Conv2D(64, 3, activation='relu', padding='same', kernel_initializer='he_normal')(inputs)
conv1 = Conv2D(64, 3, activation='relu', padding='same', kernel_initializer='he_normal')(conv1)
pool1 = MaxPooling2D(pool_size=(2, 2))(conv1)
# Continue building the U-Net architecture...
model = Model(inputs=inputs, outputs=conv10)
model.compile(optimizer=Adam(lr=1e-4), loss='binary_crossentropy', metrics=['accuracy'])
if pretrained_weights:
model.load_weights(pretrained_weights)
return modelThis code snippet demonstrates how straightforward it is to construct a U-Net model using convolutional, pooling, and upsampling layers, along with concatenations for skip connections.
Challenges in Semantic Segmentation
Despite the advancements in semantic segmentation, challenges remain. Gathering ground truth data for training models is a significant hurdle. Creating accurate segmentation maps for training can be labor-intensive, often requiring manual annotation or sophisticated scripts.
The Future of Semantic Segmentation
The field of semantic segmentation is rapidly evolving, with ongoing research and development leading to new architectures and techniques. As the integration of computer vision and deep learning continues to advance, we can expect to see even more innovative applications in various domains.
For those interested in diving deeper into the world of semantic segmentation and deep learning, the Advanced Computer Vision with TensorFlow course by DeepLearning.ai offers a comprehensive exploration of these topics.
In conclusion, semantic segmentation is a vital area of research with significant implications for real-world applications. As we witness the fusion of technology and innovation, the future of semantic segmentation promises to be both exciting and transformative. Whether in autonomous vehicles or medical diagnostics, the ability to understand images at a pixel level will undoubtedly shape the way we interact with the world around us.