
{kind=link}
The Evolution of Deep Learning: A Journey Through Convolutional Neural Networks
In the realm of artificial intelligence, the past decade has witnessed a remarkable transformation, particularly in the field of deep learning. From the groundbreaking success of AlexNet in 2012 to the sophisticated architectures of today, the progress has been nothing short of astounding. Back in 2012, AlexNet achieved a Top-1 accuracy of 63.3% on the ImageNet dataset, a feat that was celebrated as a monumental leap forward. Fast forward to today, and we are now surpassing 90% accuracy with advanced models like EfficientNet and innovative training techniques such as teacher-student training.
A Visual Representation of Progress
If we were to visualize the accuracy of various models on ImageNet over the years, it would illustrate a clear upward trajectory, showcasing the relentless pursuit of improvement in image classification tasks. The graph below encapsulates this evolution, highlighting the significant milestones achieved by different architectures.
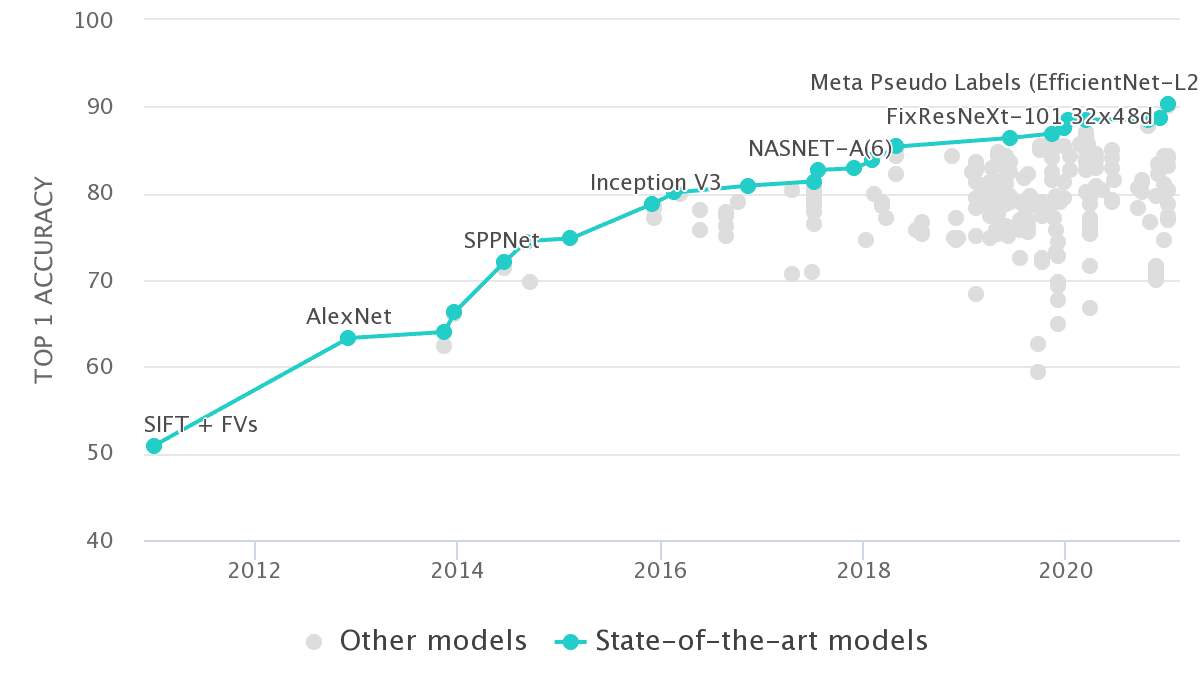
Source: Papers with Code – Imagenet Benchmark
To further understand this evolution, we can condense the top-performing convolutional neural networks (CNNs) until 2018 into a single image. This visual representation not only showcases the architectures but also emphasizes the underlying principles that have driven their development.
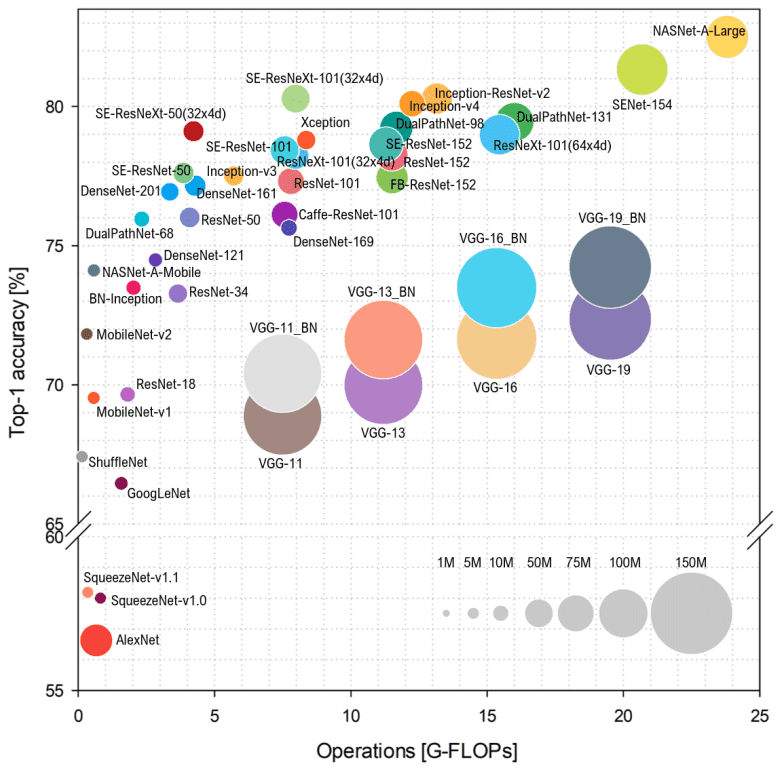
Source: Simone Bianco et al. 2018
Key Terminology in CNNs
Before diving into the specifics of each architecture, it’s essential to define some key terminology that will help us navigate the discussion:
- Wider Network: Refers to having more feature maps (filters) in the convolutional layers.
- Deeper Network: Indicates an increase in the number of convolutional layers.
- Higher Resolution Network: Processes input images with larger spatial dimensions, resulting in feature maps with higher spatial resolutions.
Understanding these terms is crucial as we explore the engineering of CNN architectures and their scaling strategies.
The Birth of AlexNet (2012)
AlexNet marked a pivotal moment in deep learning history. Comprising five convolutional layers and utilizing an 11×11 kernel, it was the first architecture to effectively leverage max-pooling layers, ReLU activation functions, and dropout techniques to combat overfitting. Trained on the ImageNet dataset with 1,000 classes, AlexNet’s architecture was revolutionary for its time.
Here’s a simplified implementation of AlexNet in PyTorch:
class AlexNet(nn.Module):
def __init__(self, num_classes: int = 1000) -> None:
super(AlexNet, self).__init__()
self.features = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=11, stride=4, padding=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(64, 192, kernel_size=5, padding=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(192, 384, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(384, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(256, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
)
self.avgpool = nn.AdaptiveAvgPool2d((6, 6))
self.classifier = nn.Sequential(
nn.Dropout(),
nn.Linear(256 * 6 * 6, 4096),
nn.ReLU(inplace=True),
nn.Dropout(),
nn.Linear(4096, 4096),
nn.ReLU(inplace=True),
nn.Linear(4096, num_classes),
)
def forward(self, x: torch.Tensor) -> torch.Tensor:
x = self.features(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.classifier(x)
return xAlexNet not only set the stage for future architectures but also highlighted the importance of using GPUs for training deep networks, a practice that was still in its infancy at the time.
VGG: The Deep Learning Revolution (2014)
The introduction of VGG networks further solidified the concept of depth in CNNs. The paper “Very Deep Convolutional Networks for Large-Scale Image Recognition” demonstrated that simply adding more layers could enhance performance, albeit up to a certain limit. VGG utilized small 3×3 kernels stacked in layers, which allowed for a more discriminative feature extraction process.
The architecture’s design philosophy was to reduce the number of parameters while increasing the depth, leading to better generalization. VGG models remain popular for various applications, including feature extraction in generative adversarial networks and style transfer.
InceptionNet/GoogleNet: A New Paradigm (2014)
The Inception architecture, introduced in the paper “Going Deeper with Convolutions,” revolutionized the way we think about network design. It emphasized the need to balance depth and width while maintaining computational efficiency. By employing 1×1 convolutions for dimensionality reduction, Inception modules allowed for the processing of inputs at multiple scales, leading to improved performance without a significant increase in computational cost.
The architecture’s innovative design paved the way for subsequent models, including Inception V2 and V3, which further refined the principles established by the original InceptionNet.
ResNet: Overcoming the Vanishing Gradient Problem (2015)
ResNet introduced a groundbreaking concept: residual learning. By allowing gradients to flow through skip connections, ResNet architectures could be trained with significantly more layers without suffering from vanishing gradients. This innovation enabled the creation of very deep networks, ranging from 18 to 152 layers, while maintaining high accuracy.
The introduction of bottleneck layers further optimized the architecture, making it feasible to train deeper models efficiently. ResNet’s success has led to its widespread adoption across various domains, including image classification, object detection, and more.
DenseNet: Feature Reuse and Efficiency (2017)
DenseNet took the idea of skip connections to the next level by concatenating feature maps from all previous layers. This approach not only encouraged feature reuse but also resulted in more compact models with fewer parameters. DenseNet’s architecture allowed for efficient training and improved performance, particularly in tasks where feature reusability is crucial.
EfficientNet: A New Standard in Model Scaling (2019)
EfficientNet represents a paradigm shift in model scaling. By carefully designing the architecture and employing compound scaling, EfficientNet achieves state-of-the-art performance with significantly fewer parameters compared to previous models. The architecture’s ability to balance depth, width, and resolution simultaneously has set a new standard for efficiency in deep learning.
Teacher-Student Training: Enhancing Performance (2020)
The introduction of teacher-student training, particularly through the Noisy Student method, has further improved model performance. By leveraging unlabeled data and iteratively refining the model, this approach has demonstrated remarkable success in enhancing accuracy on challenging datasets like ImageNet.
Conclusion: A Journey of Innovation
The evolution of convolutional neural networks over the past decade has been marked by continuous innovation and improvement. From AlexNet’s groundbreaking success to the sophisticated architectures of today, each model has contributed to our understanding of deep learning and its applications.
As we look to the future, the focus will undoubtedly shift towards more efficient architectures, leveraging large-scale datasets, and refining training methodologies. The journey of deep learning is far from over, and the possibilities are limitless.
For those interested in diving deeper into the world of deep learning, consider exploring resources like Andrew Ng’s courses or engaging with hands-on projects to solidify your understanding. The future of computer vision and deep learning is bright, and now is the perfect time to be a part of it.